一、索引
索引是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
我们对表的某个字段添加索引,会把这个字段的所有行都转换成数字按照B-tree的形式存放在索引表当中,如下:
30 10 40 5 15 35 66 1 6 11 19 21 39 55 100
可以看到,对于索引表当中的每一个数字来说,所有比它小的数字都在它的左边,比它大的数字都在它右边。每一行存放的是2的n次方个数字。如果我们需要在1024条数据中找到想要的那一条,最多只需要查找10次就能查到。而如果没有建立索引,则可能需要查找1024次才能查到,这就是为什么索引能够提高查询速度的原因了。
二、索引的种类
MySQL中常见索引有:
- 普通索引:仅加速查询;
- 唯一索引:加速查询 + 列值唯一(可以有null);
- 主键索引:加速查询 + 列值唯一(不可以有null);
- 组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于使用多个单列索引组合搜索;
1、普通索引
普通索引仅有一个功能:加速查询


1 CREATE TABLE Student(2 ID INT NOT NULL auto_increment PRIMARY KEY,3 Name VARCHAR(20) NOT NULL,4 Email VARCHAR(64) NOT NULL,5 Extra text,6 INDEX index_Name(Name) // 普通索引7 )
1 CREATE INDEX index_Name ON Student(Name);2 ALTER TABLE Student ADD INDEX index_Email(Email);
1 DROP INDEX index_Name(索引名) on Student(表名);
1 SHOW INDEX FROM Student(表名);
注:如果创建索引的列是BLOB或TEXT类型,必须指定长度,如下:
1 CREATE INDEX index_Extra ON Student(Extra(32));
2、唯一索引
唯一索引有两个功能:加速查询 和 唯一约束(可含null) 1 CREATE TABLE Student(2 ID INT NOT NULL auto_increment PRIMARY KEY,3 Name VARCHAR(20) NOT NULL,4 Email VARCHAR(64) NOT NULL,5 Extra text,6 UNIQUE unique_Name(Name) // 唯一索引7 )
1 CREATE UNIQUE INDEX unique_Email ON Student(Email);2 ALTER TABLE Student ADD UNIQUE unique_Email(Email);
1 DROP INDEX unique_Email on Student;
3、主键索引
主键索引同样有两个功能:加速查询 和 唯一约束(不可含null)
1 CREATE TABLE Student( 2 ID INT NOT NULL auto_increment PRIMARY KEY, // 主键索引 3 Name VARCHAR(20) NOT NULL, 4 Email VARCHAR(64) NOT NULL, 5 Extra text 6 ) 7 8 或 9 10 CREATE TABLE Student(11 ID INT NOT NULL auto_increment,12 Name VARCHAR(20) NOT NULL,13 Email VARCHAR(64) NOT NULL,14 Extra text,15 PRIMARY KEY(ID) // 主键索引16 )
1 ALTER TABLE Student ADD PRIMARY KEY(ID);
1 ALTER TABLE Student DROP PRIMARY KEY;2 ALTER TABLE Student MODIFY ID INT,DROP PRIMARY KEY;
4、组合索引
组合索引是将n个列组合成一个索引,其应用场景为:频繁的同时使用n列来进行查询,如:where column1 = 'Jack' and column2 = 666
普通组合索引
1 CREATE TABLE Student(2 ID INT NOT NULL auto_increment PRIMARY KEY,3 Name VARCHAR(20) NOT NULL,4 Email VARCHAR(64) NOT NULL,5 Extra text,6 INDEX index_ID_Name(ID,Name) // 组合索引7 )
1 CREATE INDEX index_ID_Name on Student(ID,Name);
联合唯一索引
1 CREATE TABLE Student(2 ID INT NOT NULL auto_increment PRIMARY KEY,3 Name VARCHAR(20) NOT NULL,4 Email VARCHAR(64) NOT NULL,5 Extra text,6 UNIQUE unique_index(ID,Name)7 )
1 CREATE UNIQUE INDEX unique_ID_Name ON Student(ID,Name);2 ALTER TABLE Student ADD UNIQUE unique_ID_Name(ID,Name);
如上创建组合索引之后,查询条件:
- ID and Name -- 使用索引
- ID -- 使用索引
- Name -- 不使用索引
注:对于同时搜索n个条件时,组合索引的性能好于多个单一索引合并
1 DROP INDEX index_ID_Name on Student;
三、使用索引和不使用索引
由于索引是为加速搜索而生,所以加上索引之后,查询速度会飞起来,下面我们来看一下对比
如下有一张student表中有100万条数据,ID列为主键索引,Name列为普通索引

无索引
有索引

从以上可以看出,因为Name列建立了普通索引而Email列未建索引,所以搜索速度Name列比Email快很多
四、SQL执行计划
使用 explain + 查询 SQL 能够显示 SQL 的执行信息参数,根据参考信息我们可以查看到该 SQL 是否命中索引,搜索了多少条数据等等信息,如下:

1、id
id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表示这是一个结果集,不需要使用它来进行查询。
2、select_type
- simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个;
- primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary,且只有一个;
- union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union;
- dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响;
- union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null;
- subquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery;
- dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响;
- derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select;
3、table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的<derived N>就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。如果是尖括号括起来的<union M,N>,与<derived N>类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
4、type
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引。
- system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index;
- const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描;
- eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref;
- ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现;
- fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引;
- ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多;
- unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值;
- index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重;
- range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中;
- index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取多个索引,性能可能大部分时间都不如range;
- index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询;
- all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录;
5、possible_keys
查询可能使用到的索引都会在这里列出来。
6、key
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7、key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
8、ref
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func。
9、rows
这里是执行计划中估算的扫描行数,不是精确值。
10、Extra
这个列可以显示的信息非常多,有几十种,常用的有:
- using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据;
- using where:这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引;
- using temporary:这意味着mysql在对查询结果排序时会使用一个临时表;
- using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中;
- Range checked for each record(index map: N):这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的;
五、正确使用索引
数据库表中添加索引后确实能加快查询速度,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。
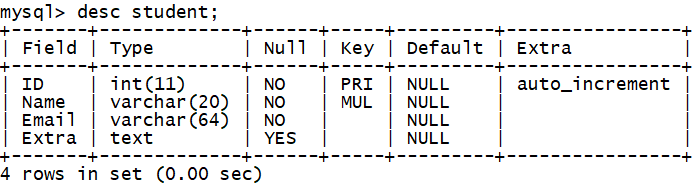
我们还是以上面这张 student 表来做示例,ID列建立了主键索引,Name列建立了普通索引,Email列和Extra列未建索引。
以下这几种情况是常见的查询未能命中索引:
1、like

从上图可以看到,当我们使用 like 进行模糊查找时,百分号(%)在最左侧时,查询未命中索引。然后我们再试试把百分号放到最右边,如下:

这时我们发现,查询命中索引了,type 为 range ,rows 为 1,查询速度会得到很大的提高。所以我们建议当一定要使用模糊查询时,百分号(%)放在最右边可以加快查询速度。
2、使用函数

从上图可以看到,我们使用函数对已经建立的索引的列进行计算或转换的时候,查询语句不能命中索引。如果一定要用,建议计算或转换右边的值,如下:
 3、or
3、or
当or条件中有未建立索引的列时,不能命中索引,如下:

如果两个条件都建立了索引,则能够命中索引,type为index_merge,如下:

但是,下面这种情况也同样能命中索引,如下:

4、类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然也不能命中索引,如下:


因为 Name 列是 varchar 类型,所以查询条件中一定要用引号括起来。
5、不等于(!=)
对于普通索引和唯一索引来说,查询条件使用了不等于(!=),则不能命中索引,如下:
普通索引


唯一索引

如果是主键,则还是会走索引,如下:

6、大于(>)
对于普通索引和唯一来说,查询条件使用了大于号(>),则不能命中索引,如下:
普通索引

唯一索引

但如果是主键索引,或者是创建索引的列是整数类型(不管是普通索引还是唯一索引),则还是会走索引,如下:
普通索引

唯一索引

主键索引

7、order by
根据索引排序时候,查询的列如果没建索引,则不走索引,如下:

查询的列如果建立了索引,则会走索引,如下:

如果是主键,则会走索引,如下:

8、组合索引
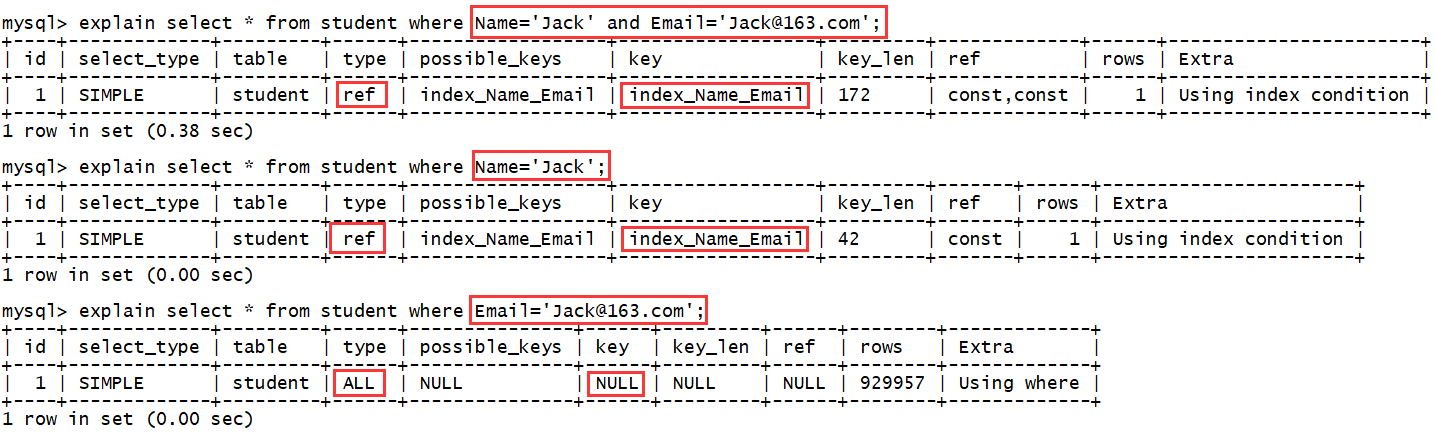
如果组合索引为:(Name,Email),如下:
- name and email -- 使用索引
- name -- 使用索引
- email -- 不使用索引
9、其他注意事项
- 避免使用select * ;
- 使用count(1)或count(列) 代替 count(*);
- 如果字段是固定长度,创建表时尽量使用 char 而不要使用 varchar;
- 创建表时定长的放前面,不定长的放后面;
- 使用组合索引代替多个单列索引(经常使用多个条件查询时);
- 使用连接(JOIN)来代替子查询(Sub-Queries);
- 尽量使用短索引,创建索引的列是BLOB或TEXT类型,必须指定长度。这时创建索引时尽量短;
- 连表时注意两张表的字段类型要一致;
- 索引散列值(重复多)不适合建索引,例:性别不适合;
- 频繁进行【增/删/改】的表不适合创建索引;频繁进行查询操作的表才适合创建索引。
六、limit分页
我们在使用 limit 做查询分页时,随着页数的增加,需要检索的数据越来越多,自然查询的速度就越来越慢,如下:
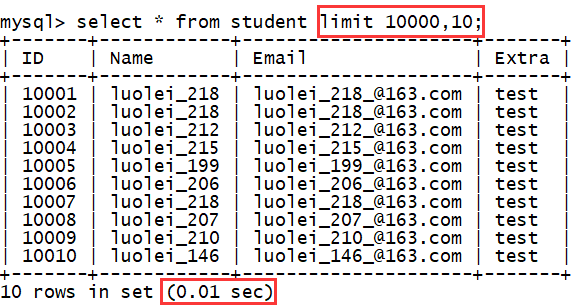
检索 10000 条数据,展示它之后的10条数据,用时 0.01 秒。
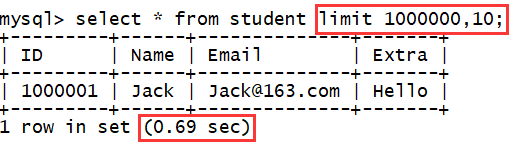
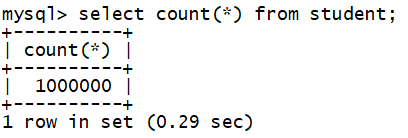
检索 1000000 条数据,展示它之后的10条数据(因该表只有1000001条数据,所以只展示一条数据),用时 0.69 秒。
如何解决这个问题呢?只要我们加一个查询条件,就能加快查询速度,如下:

我们再来看以下以上两种方式的执行计划,如下:

很明显,下面这种方式命中了索引,大大加快了查询速度。
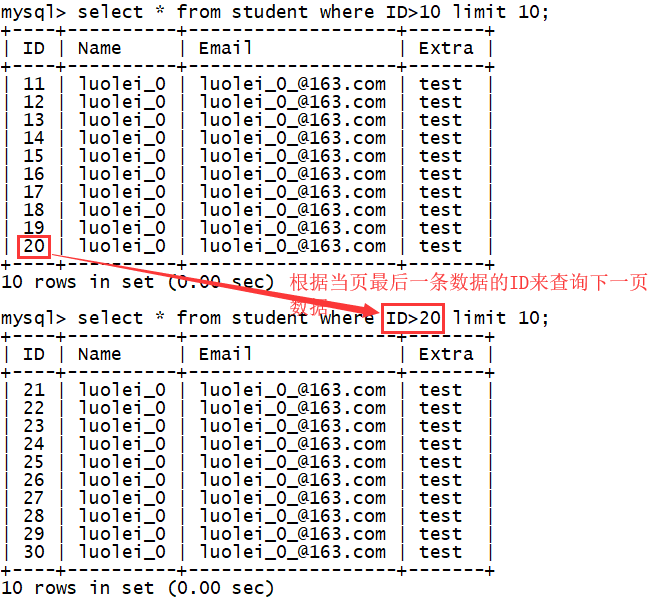
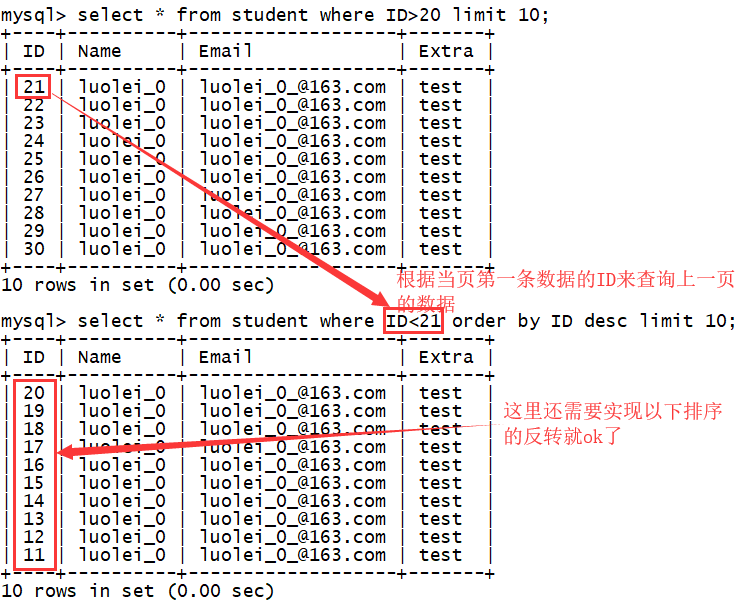
对于系统中的 “上一页” 和 “下一页” 的功能,是如何实现的呢?
只要我们获取到当页第一条数据和最后一条数据的 ID,根据当页第一条数据的 ID 来查询上一页数据,根据最后一条数据的 ID 来查询下一页数据,如下: